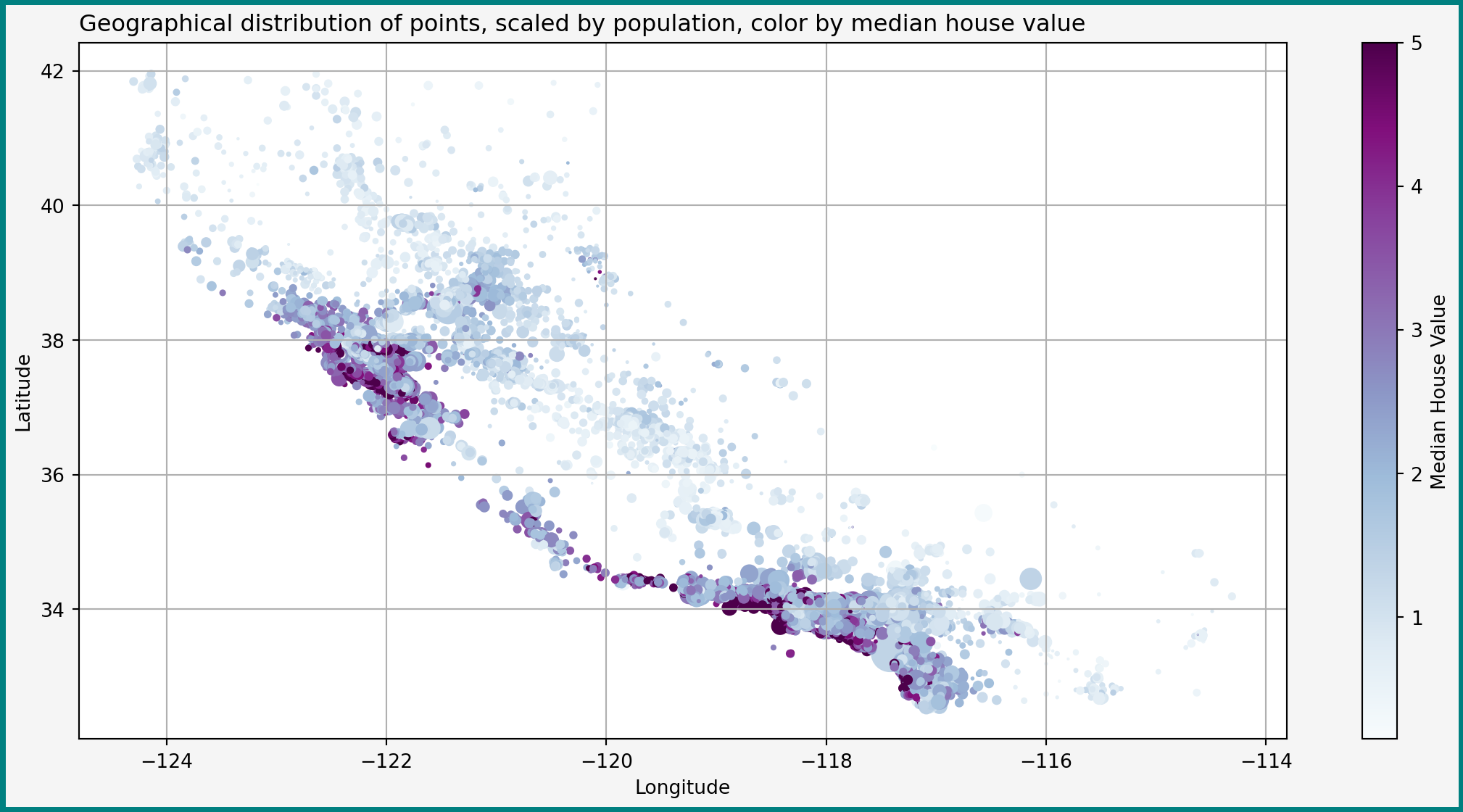
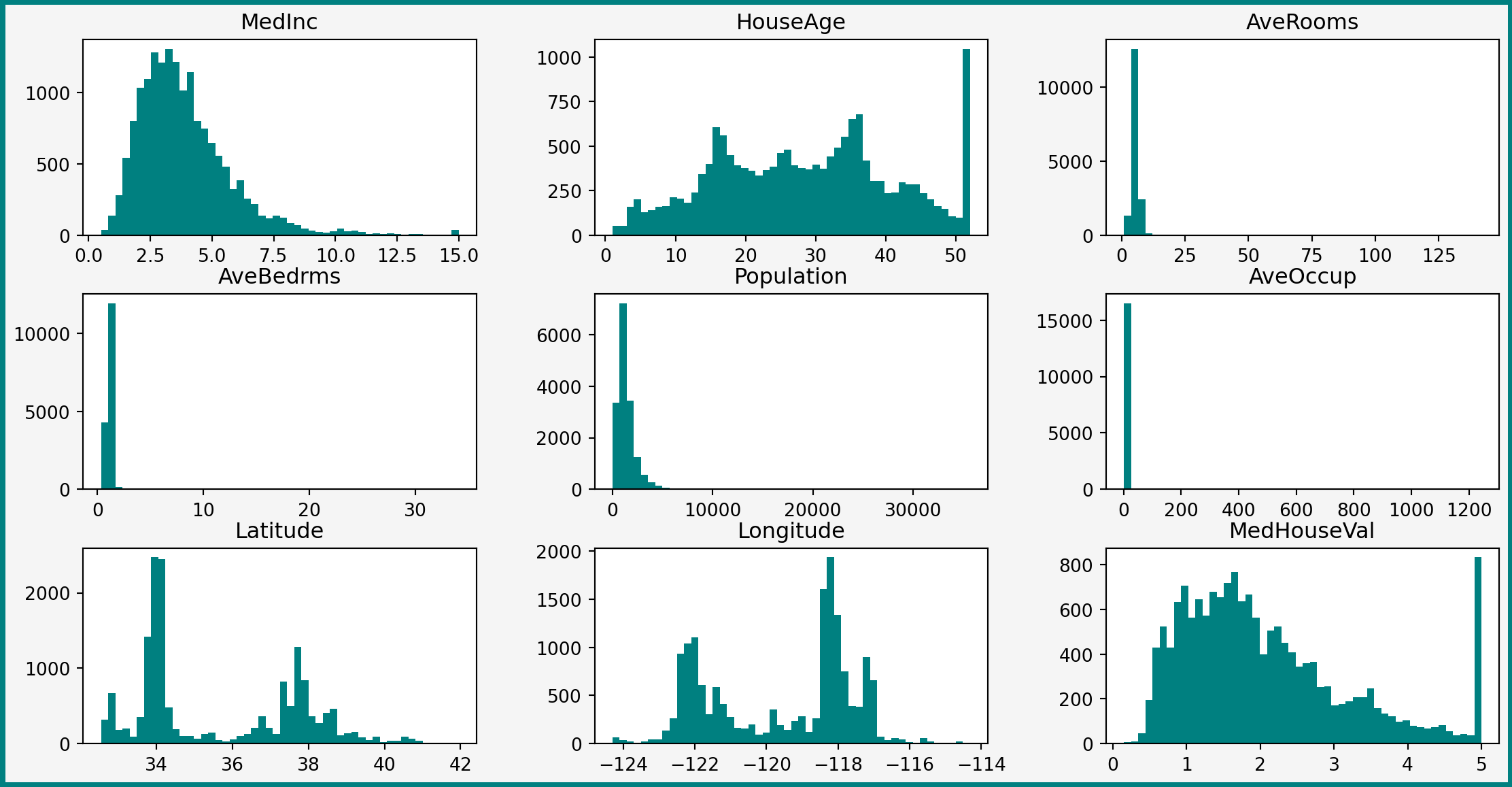
Pipeline(steps=[('extraction',
ColumnTransformer(transformers=[('bedroom_ratio',
FunctionTransformer(feature_names_out=<function ratio_name at 0x000001BCC92A76A0>,
func=<function column_ratio at 0x000001BCC8027600>,
validate=True),
['AveBedrms', 'AveRooms']),
('passthrough', 'passthrough',
['MedInc', 'HouseAge',
'AveRooms', 'AveBedrms',
'Population', 'AveOccup']),
('drop', 'drop',
['Longitude', 'Latitude'])])),
('poly', PolynomialFeatures(include_bias=False)),
('scale', StandardScaler())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.