Learning Framework, Limits and Trade-Offs
PAC Learning, Bias-Complexity Trade-Off, and the No Free Lunch Theorem
Approximation Error II
- Example: \(\Hcal_1 \subseteq \Hcal_2\) \(\subseteq \dots\) \(\subseteq \Hcal_{\gamma} \subseteq \dots\)
- Increasing \(\gamma\) — more complex class (e.g. allowing higher powers of polynomials)
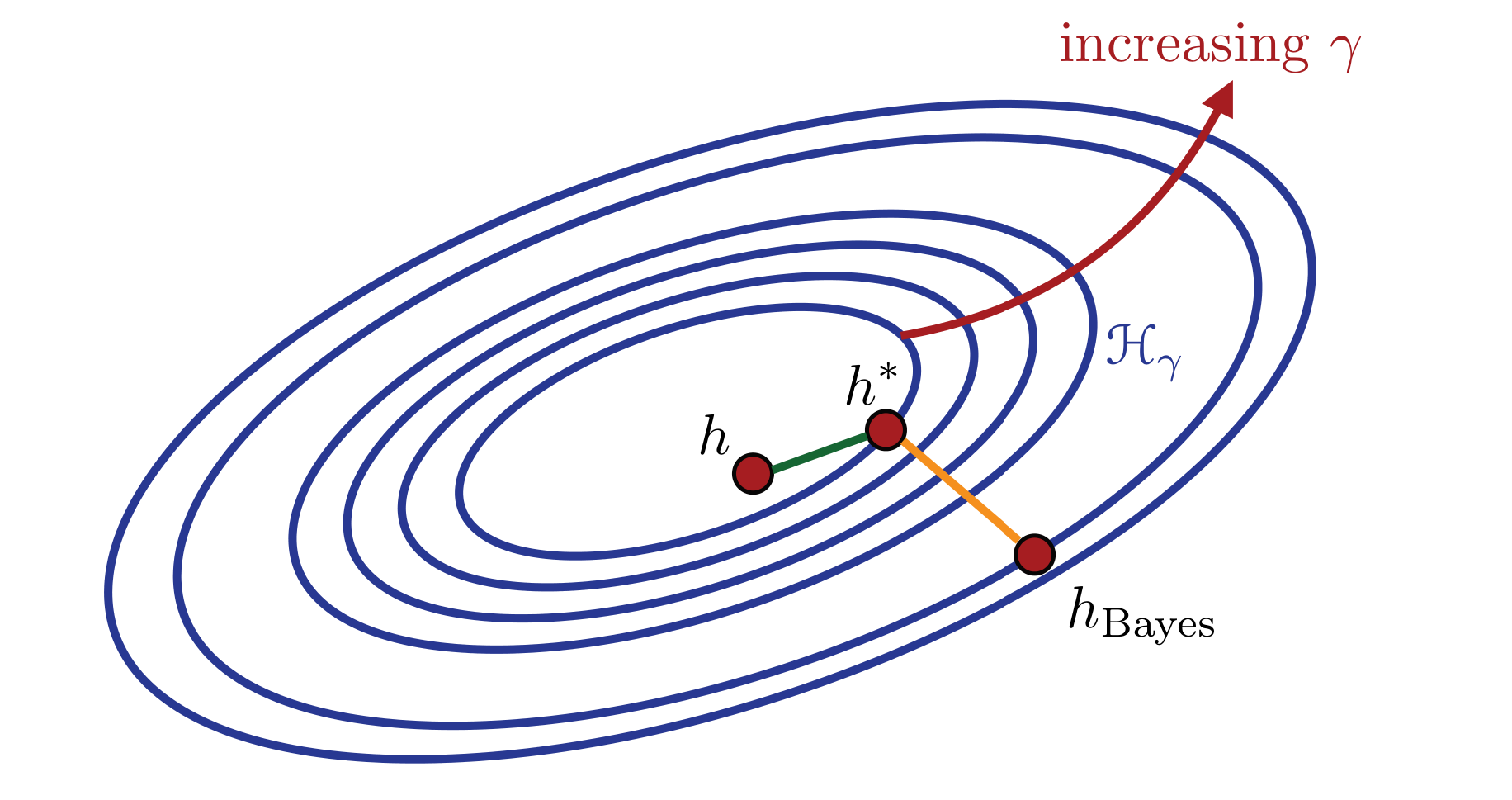
Can generally get closer to Bayes risk (e.g. by getting closer to Bayes predictor \(h_{Bayes}\))
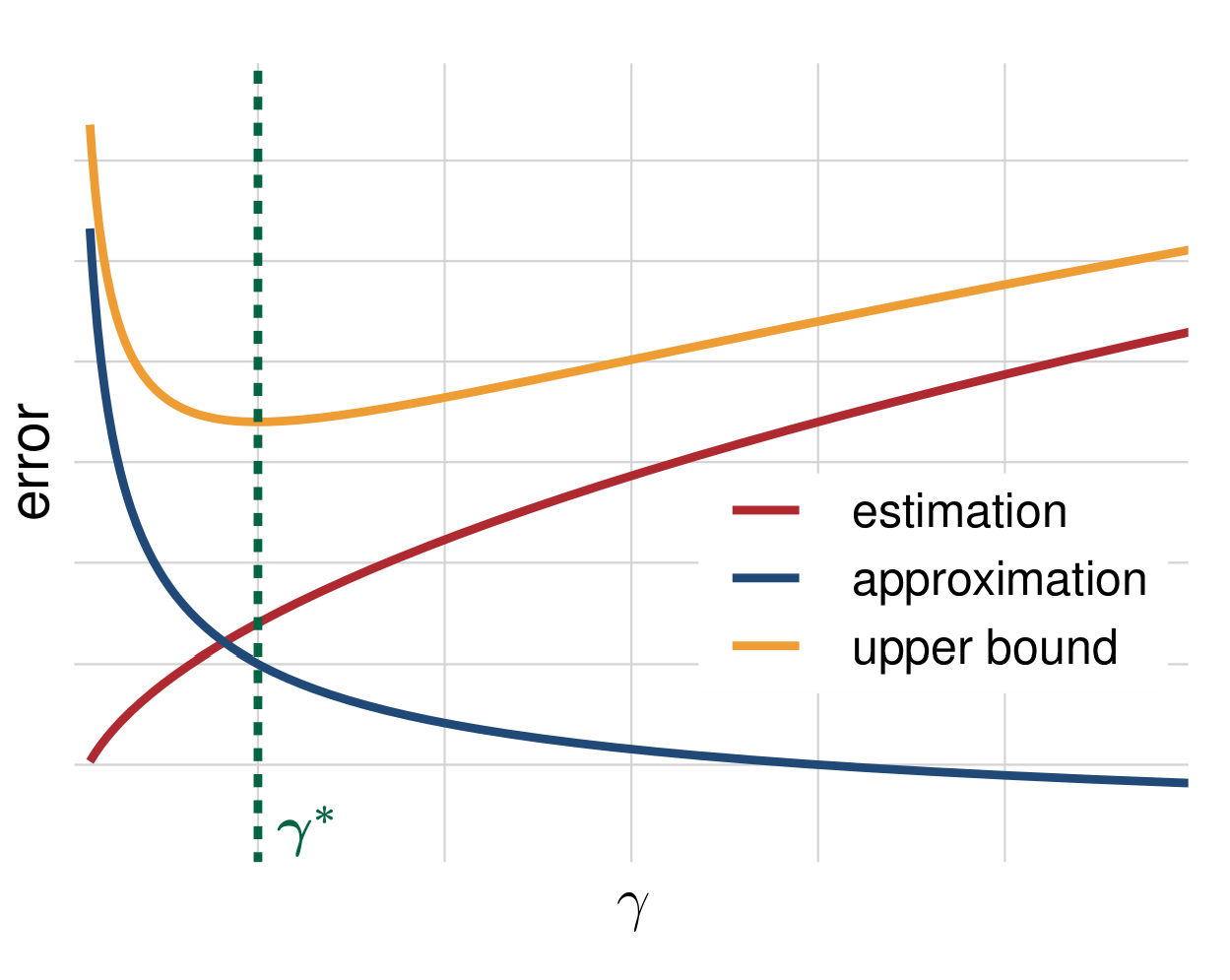
Bias-Complexity Trade-Off II: Visually
- Increasing complexity: approximation error \(\Downarrow\), estimation error \(\Uparrow\) (more or less)
- Creates a trade-off
- Finding optimal point — art. Depends on the specific problem (more on that later)
References
James, Gareth, Daniela Witten, Trevor Hastie, Robert Tibshirani, and Jonathan E. Taylor. 2023. An Introduction to Statistical Learning: With Applications in Python. Springer Texts in Statistics. Cham: Springer.
Mohri, Mehryar, Afshin Rostamizadeh, and Ameet Talwalkar. 2018. Foundations of Machine Learning. The MIT Press. https://doi.org/10.5555/3360093.
Shalev-Shwartz, Shai, and Shai Ben-David. 2014. Understanding Machine Learning. 1st ed. West Nyack: Cambridge University Press.
Valiant, Leslie G. 1984. “A Theory of the Learnable.” Communications of the ACM 27 (11): 1134–42. https://doi.org/10.1145/1968.1972.
Wolpert, David H. 1996. “The Lack of A Priori Distinctions Between Learning Algorithms.” Neural Computation 8 (7): 1341–90. https://doi.org/10.1162/neco.1996.8.7.1341.